|
FAST |
Future
Architecture and System Technology for Scalable Computing |
|
|||||
|
Research
Tools |
Contact |
|
|||||

|
|
For future scalable computing systems, we explore not only processor, memory and IO subsystem architectures but also system
hardware and software together. Especially, we aim to prototype our cool
concepts with various implementation technologies and demonstrate them with
commercial systems although we evaluate them with simulators. We have aimed
to impact the industry research and development with
our proposals, and our proposals have been evaluated and/or adopted by big
tech companies. Our recent research focuses on exploring cool memory and
networking technologies such as Compute eXpress Link (CXL) based memory
modules and various SmartNICs to make large-scale computer systems more
efficient in terms of performance, energy consumption, and cost. |

The recent technologies we have been exploring:
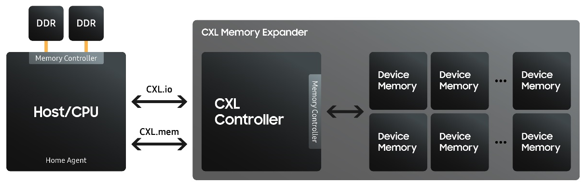
CXL Memory Expander
|
|
Modern computing
systems have demanded higher memory bandwidth. However, the current parallel
interface (e.g., DDR4) can increase neither the number of (memory) channels
nor the bit rate of the channels without paying high package and power costs.
In contrast, the high-speed serial interface (HSI) can offer much higher
bandwidth for the same number of pins and lower power consumption for the
same bandwidth than the parallel interface. This allows us to integrate more
channels under a pin and/or package power constraint but at the cost of
longer latency for memory accesses and higher static energy consumption in particular for idle channels. In our work, we first
provided a deep understanding of recent HSI (e.g., PCIe) exhibiting very
distinct characteristics from past serial interfaces in terms of bit rate,
latency, energy per bit transfer, and static power consumption. To overcome
the limitation of using only parallel (e.g., DDR) or serial (e.g., PCIe)
interfaces, we proposed a hybrid memory channel architecture-Alloy (the top
illustration) consisting of low-latency parallel and high-bandwidth serial
channels. At the architecture level, this proposal is the same as the current
CXL memory expander in which a CPU is connected to both DDR and PCIe-based
CXL (Compute eXpress Link) (the middle illustration). CXL is a high-speed
interconnect technology that enables data transfer between CPUs, GPUs, and
other devices. CXL-based memory expander technology, also known as CXL.mem,
is an extension of the CXL specification that allows for the expansion of
memory capacity beyond what is physically installed in a system.
Traditionally, memory expansion has been achieved by adding more DIMM (dual
in-line memory module) slots or increasing the capacity of existing DIMMs.
However, CXL.mem allows for the use of external memory devices, such as
high-speed DRAM or persistent memory, to expand a system's memory capacity.
This is achieved by connecting these external devices to the system via the
CXL interconnect. CXL.mem operates by using the CXL.io protocol to access the
external memory devices. The system sees the external memory devices as if
they were part of the local memory, allowing for seamless integration and
efficient access to the additional memory capacity. One of the key advantages
of CXL.mem is its high bandwidth and low latency. This allows for faster
access to data stored in the external memory devices, which can be
particularly beneficial in data-intensive applications such as machine
learning, data analytics, and high-performance computing. CXL.mem is still a developing
technology, and it is not yet widely available. However, it has the potential
to greatly increase memory capacity and performance in a wide range of
applications. |


Memory Channel Network (MCN) based Near-DRAM Processing
|
Concept
A Research Prototype based on
IBM’s Contuto and POWER8 System
An Industry Prototype by Samsung Source: Samsung |
The physical memory capacity
of servers is expected to increase drastically with deployment of the
forthcoming non-volatile memory technologies. This is a welcomed improvement
for emerging data-intensive applications. For such servers to be
cost-effective, nonetheless, we must cost-effectively increase compute throughput and memory bandwidth commensurate with
the increase in memory capacity without compromising application readiness.
Tackling this challenge, we developed Memory Channel Network (MCN)
architecture. Specifically, we first proposed an MCN DIMM, an extension of a
buffered DIMM where a small but capable processor called MCN processor is
integrated with a buffer device on the DIMM for near-memory processing.
Second, we implemented device drivers to give the host and MCN processors in
a server an illusion that they are independent heterogeneous nodes connected
through an Ethernet link. These allow the host and MCN processors in a server
to run a given data-intensive application together based on popular
distributed computing frameworks such as MPI and Spark without any change in
the host processor hardware and its application software, while offering the
benefits of high-bandwidth and low-latency communications between the host
and the MCN processors over memory channels. As such, MCN can serve as an
application-transparent framework which can seamlessly unify near-memory
processing within a server and distributed computing across such servers for
data-intensive applications. Our evaluation shows that a server with 8
MCN DIMMs offers 4.56X higher throughput and consume 47.5% less energy than a
cluster with 9 conventional nodes connected through Ethernet links, as it
facilitates up to 8.17 times higher aggregate DRAM bandwidth utilization.
Then, we demonstrated the feasibility of MCN with an IBM POWER8 system and an
experimental buffered DIMM. We are the first
research group proposed a DIMM-based near-DRAM
computing (NDA: Near-DRAM acceleration architecture leveraging commodity DRAM
devices and standard memory modules, HPCA 2015). and this MCN-based near-DRAM
processing work became the foundation for Samsung’s AxDIMM, and Samsung and
Meta jointly evaluated its efficacy for accelerating Deep Learning
Recommendation Model (DLRM). The
AxDIMM has been ued as a popular platform to explore various near-DRAM
processing concept until the CXL-based memory modules were introduced to
industry researchers. |



Processing-In-Memory (PIM)
|
An Industry Prototype by Samsung
Integration with Commercial
Products |
The performance of
modern computing systems is bottlenecked by the off-chip communication
bandwidth and its energy cost. Integrating the accelerators within DRAM
(i.e., PIM) can mitigate these bottlenecks and additionally expose them to
the higher internal bandwidth of DRAM. However, such an integration is
challenging, as should not disturb the highly-optimized
DRAM core circuitry. To enable the integration, this work proposed an
integration of a SIMD acceleration unit with each DRAM bank (the top
illustration). Later, Professor Kim
worked with talented Samsung engineers and researchers to further develop an
industry version of an advanced PIM architecture similar to
what he proposed (i.e., integration of SIMD units with DRAM banks). For a
commercial success, he aimed to develop a PIM architecture that does not
demand any change to (1) the existing processor architectures and (2) the
existing DRAM interface so that the PIM device can be a drop-in-replacement
of standard DRAM device; this development philosophy was inspired by the
success of SSD which was initially developed as a drop-in-replacement of HDD
although it began to use an interface specialized for SSD later. The PIM architecture was implemented in
HBM2 (HBM-PIM) (the middle illustration), and later HBM-PIM was integrated
with Xilinx U280 (the bottom illustration), AMD MI-50 GPU, and AMD MI-100
GPU. This PIM architecture became the foundation of a JEDEC HBM3-PIM standard
later. |



News
|
4/11/2024 |
[Fellowship]
Congratulations to Jiaqi Lou and Yan Sun for receiving Wen-mei Hwu Fellowship
and Rambus Fellowship |
|
2/27/2024 |
[Award]
Professor Nam Sung Kim won the Intel's 2023 Outstanding Researcher Award. |
|
12/18/2023 |
[Honor] Professor Nam Sung Kim was
elevated to National Academy of Inventors (NAI) Fellow. |
|
11/10/2023 |
[Award] `Improving
System Performance by Offloading Memory-Intensive Kernel Features to CXL
Type-2 Device’ work received the best demo award at the SRC/DARPA JUMP 2.0
annual review meeting. Congratulations to Harry and Yan! |
|
10/3/2023 |
[Award] `
Making sense of using a SmartNIC to reduce
datacenter tax from SLO and TCO perspectives’
received a Best Paper Runner-up Award from IISWC. Congratulations to
Jinghan, Jiaqi, Yan, and Jerry! |
|
7/1/2023 |
[Honor] `Drowsy Caches: Simple Techniques for Reducing
Leakage Energy’ published at ISCA in 2002 is selected as one of ISCA@50
Retrospective papers. |
|
6/10/2023 |
Congratulations!
Dong Kai (Edward) Wang successfully completed his Ph.D. defense and joins the
University of Illinois, Urbana-Champaign as a Teaching Assistant Professor! |
|
11/28/2022 |
The
contract is signed today! I will co-lead the SRC/DARPA JUMP 2.0 Intelligent Memory
and Storage Center (PRISM: PRocessing In Storage and Memory), starting
January 2023. |
|
11/11/2022 |
Congratulations!
Youjie Li successfully completed his Ph.D. defense and joins Meta as a
Researcher! |
|
6/30/2022 |
Congratulations!
Yifan Yuan successfully completed his Ph.D. defense and joins Intel Research
as a Sr. Research Scientist! |
|
1/12/2022 |
[Honor] Professor Kim’s work on PIM hardware architecture
and software stack, “Hardware Architecture and Software Stack for PIM Based on Commercial
DRAM Technology” was recognized as Honorable Mention by IEEE Micro Top Picks. |
|
11/9/2021 |
[Technology
Transfer] The
software code developed for our work published in
ISCA will be part of Intel’s RDT
software package! |
|
10/4/2021 |
[Award] Professor Kim’s 2003 IEEE/ACM International
Symposium on Microarchitecture (MICRO) paper got SIGMICRO Test of Time Award |
|
8/4/2021 |
[Honor] Professor Kim is named the W.J.
‘Jerry’ Sanders III – Advanced Micro Devices, Inc. Endowed Chair |
|
3/4/2021 |
[Industry’s
first HBM-based PIM Solution] Professor Kim’s work on PIM hardware architecture and software stack, “Hardware Architecture and Software Stack for PIM
Based on Commercial DRAM Technology” got accepted by ISCA 2021! |
|
3/3/2021 |
[Invited
Talk] Professor Kim gave a keynote speech on his PIM
work at HPCA! |
|
2/18/2021 |
[World’s
first HBM-based PIM Chip] Professor Kim’s paper on the industry’s first HBM Processing In Memory (PIM) chip will be presented at ISSCC! [Samsung’s
Press Release, Youtube Press Release, ZDNet,
Tom’s
Hardware] |
|
1/13/2021 |
[Honor] Professor Kim was elevated to ACM Fellow [ACM Press
Release]. |
|
1/11/2021 |
[Honor] BabelFish: Fusing address translations for containers appeared in ISCA 2020 was selected as one of
IEEE Micro Top Pick 2021 papers. |